re:Invent 2017: Tuesday Night Live の裏番組で

行ってきました re:Invent。 ミクシィグループで他の方のレポート ^1 ^2 も出ていますが今回は日本語でも英語でもほとんど情報がでていないセッション、 ARC214 - Addressing Your Business Needs with AWS をご紹介します。
ラスベガス入りして 3 日目、とにかく会場が広くて疲れ気味だったことから Tuesday Night Live は体力的に厳しいと判断、裏番組のこのセッションへの参加を決めました。
謎のセッション
そもそも、このセッションはスライド ^3 以外に全く情報がないのですが、これには以下のような理由があると思われます。
- AWS の利用が浅い (もしくはまだ利用していない) 方が多く参加していた。このような参加者は twitter や blog でセッションの内容を報告しにくい
- 新機能発表の場ではない。拡散したくなる情報がない
- Tuesday Night Live の裏番組の時間であり、参加者の絶対数が少ない (30 人程度)
- ずっとディスカッションしていて twitter やる暇がない
セッションの目的は自身の経験をシェアし、他の AWS 利用者とのコラボレーションを深めましょうといったところです。
unconference とは
まず冒頭、このセッションは unconference スタイルで進めますよという説明があります。 unconference とは、
- 参加者相互のディスカッションが中心
- 話題に制限を設けない
前提でのグループディスカッションのことです。 re:Invent の他のワークショップがほとんど ハンズオン形式で進むのに対し、このセッションは参加者相互のディスカッションによって成立するものです。つまり、このセッションの約 2 時間、議論を理解した上で発言が求められます。理解できなくても時間が過ぎていく他のセッションとは一味違います。
議論のはじまり
ファシリテーターとなった講師の進行で、各自の自己紹介からセッションがはじまります。SNS mixi を AWS に移行した経験があったので、「おれたちはでかくて古い perl のプログラムをオンプレから AWS に移したんだぜ」で自己紹介を乗り切りました。同じグループには、世界的に有名なハードウェアベンダのセキュリティアナリストもいました。 その後各テーブルで各々が直面している課題や興味のあるトピックを出していきます。「オンプレをフォークリフトアプローチ (構成をなるべく変えずにそのまま AWS に持っていく) で移してしまったので、マネージドサービスへの移行に課題感がある」という感じ。
ひととおりテーブルごとに課題を出し終わった段階で、各テーブルでディスカッションした内容を報告しあい、問題となっているテーマを大きなくくりでまとめます。ここで出たおおきなテーマのくくりごとに、テーブルを移動してさらに議論を深めます。
マネージドサービスへの移行を課題として出していたので、「 migration/integration 」のテーブルに移動。ここで驚いたのは、「まだ AWS への移行をはじめていない」というユーザが多数派だったことです。 AWS のヘビーユーザが多くを占める re:Invent でこのような人々が集まることは、珍しいことだといえるでしょう。
あるあるネタ
各参加者が報告した課題は以下のようなものでした。
クラウド利用にあたっては一般的に意識される問題でしょう。 これに対して出た意見は以下のようなものでした。
- たしかに、クラウドにあるかどうかって顧客にとってはどうでもいいことだよね
- コスト、仕方ないよねー、おれも高いと思う (「GCP にしたらやすくなるかもよ」、はぐっとこらえた)
- EU や 中国でも、各地域のリージョン使えばデータ移動規制は遵守できるんじゃないの?
など。
我々はどうしたのか
今回、特に データセンタから AWS への移行をどうしようかという方が複数おられたので、mixi の AWS 移行で実施した以下の経験を話しました。
- AWS Direct Connect でデータセンタと VPC をつないで移動させやすいアプリケーションサーバから検証、移動をはじめた
- 仮に AWS への移行が頓挫したとしても、オンプレでの構成を維持できる状態で検証を進めた
- アプリケーションサーバに比べて動かしにくい DB の移行は最後に回した。ここで、Aurora や RDS も検証したが、結局は mysql を EC2 で動かすことを選択した
特にデータストアの移行を後回しにし、AWS への移行が失敗した場合のリスクを最小限にするアプローチについては interesting というコメントをいただけました。また、「それって遅延とかだいじょうぶだったの?」 という質問をいただき、 memcached を VPC 側にも作って read のトラフィックは VPC と DC の中で完結するようにしたよという回答をしています。
まとめ
このセッションでは新機能の発表や AWS 実装の裏側に関する新しい知識を得ることはありませんでした。 しかしながら、他の参加者と本音ベースの知識をシェアできたという経験、なにより自身の経験を振り返って自信を持てたという点においては、他のセッションでは得がたい充足感がありました。
re:Invent 2016 でも 同じタイトルで unconference スタイルのセッションがあったようです ^4 。今回は 2016 年から続けて 2 回目。他の参加者との交流のきっかけを掴みたい方に、 unconference はぜひおすすめしたいセッションです。
AWS DeepLens はしっかりゲット

Vienetian の食堂。めちゃくちゃ広い。世界最大級のカンファレンスを捌くには効率的に飯を食わせるノウハウが不可欠

re:Play Party の熱気
Internet Week 2017「高信頼性運用を実現するSREという新潮流」登壇レポート
※こちらの記事は過去のブログから転載したものです。
こんにちは。
最近、3種類のスマートスピーカーを手に入れて、目の前に並べてひとりニンマリしている杉田です。普段は、XFLAG スタジオでTech PRを担当しています。
さて、少し遅くなりましたが、今日は、11/27(月)〜12/1(金)まで開催された『Internet Week 2017』にて、XFLAG スタジオ SREの清水が登壇させていただいたので、簡単ですが、レポートさせていただきます。
「高信頼性運用を実現するSREという新潮流」というセッション枠で、株式会社ハートビーツ様にお誘いいただき、モンスターストライクでのSREの組織化について、お話をさせていただきました。
『モンスターストライクの信頼性を支えるSREの組織化について』
現在のSREグループの業務は、元々はSNS「mixi」などの大量トラフィックや大規模データを持つサービスの安定性や継続的な改善、機能追加などを実現するために、ネットワークやサーバーの調達などを担っていた運用部の「インフラ」チームと、サーバ構築・運用、ミドルウェアのチューニングや負荷対策、デプロイ環境の整備など、同じく運用部の「アプリ運用」と呼ばれるチームの業務を、ソフトウェアエンジニアリングによせて、アプリケーション開発側と効率的に連携し、徹底的にサイトの信頼性を支えることに注力できる様、設立されました。さらに、運用部と連携していた「たんぽぽ」グループの "開発者を「刺し身の上にタンポポをのせる仕事」から解放する"というミッションも継承するような形になっています。
世界累計4,000万人を超えるユーザーを抱えるモンスターストライクのサイト信頼性は、SREなしでは語れないとも言えます。
そんなモンスターストライクでのSREについて、求められている役割や、仕事の進め方、人事評価のポイントまで、これからSRE組織を設立していきたいという方々の参考にしていただけたらと思うことをご紹介させていただきました。
エックスフラッグスタジオでは、エンジニアも積極採用中です。
ご応募お待ちしております。
https://career.xflag.com/career/#engineer
CREチームを設立しました!
※こちらの記事は過去のブログから転載したものです。

mixiグループ Advent Calendar 2017 の2日目の記事です。
初めまして。XFLAG スタジオの豊川です。
このたびXFLAG スタジオではCREチームを設立しました!
...と言われても「CREとはなんぞや?」となってしまいますよね。
そこで今日は、CREについて私たちの取り組みを交えてご紹介します。
CREと私たち
SRE (Site Reliability Engineering) は今ではよく聞かれるようになりました。
XFLAG スタジオにもSREグループがあり、このブログでも度々目にします。
一方、CREはまだ馴染みがありません。CREとは Customer Reliability Engineering です。
CREはSREと同じく Googleが提唱した 役割で、先日はてなさんもCREチームの設立を発表しました。
SREがシステムの信頼性を関心の対象としているのに対し、CREはその名の通りお客様の信頼、つまり、不安を抱えるお客様に寄り添うことに主眼を置いています。
意外に思われるかもしれませんが、私たちCREチームにとってのお客様とは、ゲームを遊んでくださっているユーザーだけではありません。
私たちは、前身はカスタマーサポート (CS) 部門専任の開発チームで、CSスタッフのための管理画面を開発し、お問い合わせフォームを用意し、寄せられた事柄や不具合についてプロダクト提供者である社内の開発部門と協力して解決に取り組んできました。
私たちCREチームにとってお客様とは、XFLAGのコンテンツを楽しんでくださっているユーザーであり、助けを必要としているユーザーに手を差し伸べるCSスタッフであり、アドレナリン全開のコンテンツをお届けするプロダクト提供者でもあるのです。
ユーザー・CSスタッフ・プロダクト提供者という三者の信頼の最大化こそが、私たちCREチームのミッションです。
CREチームの取り組み
お客様との信頼を築くためのCREチームの取り組みをご紹介します。
問い合わせ対応の際、CSスタッフはユーザーの情報を確認します。
確認方法は各社・各サービスによって様々で、CSスタッフ向けの管理画面 (以下、CSツール) が多いようですが、中にはアプリケーションフレームワーク付属のDB管理画面を使っているという話も耳にします。誤ってデータを消してしまったら...想像したくないですね(笑)
今やゲームアプリは毎月のようにバージョンアップがあります。が、残念なことにCSツールはなかなか機能追加されないと聞きます。
実のところ、プロダクトの機能開発を優先し、CSが後回しになるという構図は珍しくありません。
CSが困っているお客様の信頼に応えることができなければ、お客様は去っていってしまいます。

私たちはモンスターストライク (以下、モンスト) やファイトリーグをはじめとする全てのプロダクトで、CSのための環境を整備しています。
モンストは今秋4周年を迎えましたが、モンストのCSツールも4周年を迎えようとしています。
モンストではこれまで幾度となくバージョンアップがあり、多くの機能が追加されてきましたが、驚くべきことにCSツールもほぼ同時に機能追加が行われてきました。
CSスタッフが常に確実な情報を元に対応できるということは、不安を抱えるお客様に寄り添う体制が常にできているということです。言うなれば、お客様の信頼においてダウンタイムがないのです。
信頼構築のための取り組みをもう1つご紹介します。
問い合わせの中には、技術的な調査を要するものがあります。
そしてそれらはプロダクト開発のエンジニアが担当するのが一般的なようです。
しかしながら、彼らには次のバージョンに向けた機能開発があります。必然的に、機能開発と調査のどちらを優先するかという問題に直面します。
CREチームは一次調査を引き受けます。調査の結果、CREは必要であれば担当者に割り振りますが、可能であれば修正パッチを作り Pull Request します。
これにより、プロダクト提供者は機能開発に専念することができ、CSはお客様を素早くサポートできるようになるのです。
私たちCREは、信頼獲得のためあらゆる技術的アプローチを駆使します。よって、その技術領域は、フロントエンド、サーバーサイドはもちろん、ブラウザ組み込みスクリプトやCRMプラットフォームアプリの開発、ログの解析など多岐にわたっています。
mixiグループ Advent Calendar 2017 では、他のCREメンバーがより詳しい取り組みや各々が興味のある技術についてご紹介します。ぜひご覧になってくださいね!
イベントレポート:Roomba(ルンバ)とフロントエンドとIoT
※こちらの記事は過去のブログから転載したものです。
こんにちは。XFLAG スタジオのキャリア採用担当です!
XFLAG スタジオの理解を深めていただくため、こちらでは"XFLAG スタジオ活動報告"を配信しています。今回は、弊社フロントエンドエンジニア梅山の登壇レポートです。
~ *** ~
XFLAG スタジオのフロントエンドエンジニアは、モンスターストライク(以下、モンスト)やファイトリーグ™などの公式サイトや数多くのキャンペーン特設サイトの制作を担当しています。その他にもリアルイベントで使用するデジタルサイネージの制作も担当しています。
※過去の制作例はこちらからご覧ください。
https://www.monster-strike.com/promotion/kiwami2017/
https://fight-league.com/
そんなフロントエンドエンジニアの一人である梅山が、先日、とあるイベントのLT枠にて発表させていただきました!その名も。。。
『 Frontend de KANPAI! #02 - エンジョイ!フロントエンド - 』
「Frontend de KANPAI!」は、フロントエンドエンジニアやフロントエンドに興味のある方達が集い、ドリンク片手にゆるく交流する、DeNAさん主催のイベントです。
そんなイベントで登壇した梅山のテーマは、、、
「Roomba(ルンバ)とフロントエンドとIoT」


なんと梅山家では、モンストでキャラクターの必殺技を繰り出す際のセリフである『ストライクショット』を叫べば、ルンバが動き出すそうです。(笑)
実際に、本人が叫んでいる映像はこちら!
真面目な話を少しすると、、、
そもそも梅山自身がどのような人物かといいますと、作業の効率化に対し、とても強い情熱をもったフロントエンドエンジニアです。そして、今回家庭内IoTをテーマにあげたのも、「家庭内IoTを体験することで、普段の業務領域だけでは思いつかなかった、自動化・改善のアイデアにたどり着く!」という実体験を伝えたいという想いからでした。
是非当日の登壇資料もご一読ください!
~ *** ~
XFLAG スタジオには、梅山のように作業の効率化に強い情熱をもったエンジニアもいれば、ギミック実装に燃えるエンジニアもいます。
今後も、その他の職種も含め、スタジオメンバーの登壇機会がありましたら、またレポートします!

XFLAG スタジオでは現在採用を強化しています。
採用情報はこちらからご覧ください 。
https://career.xflag.com/career/
その他のレポートはこちら:https://career.xflag.com/report/
社員インタビューはこちら:https://career.xflag.com/interview/
Char2Vec で文字の特性について調べてみた
ミクシィ Vantage スタジオのAI・ロボットチームで自然言語処理関連の研究開発に関わっている原(@toohsk)です.
Vantage スタジオでは人の感情に寄り添った会話ができるAIの研究開発を通じて,新しいコミュニケーションサービスを生み出そうとしています. 今回, Char2Vec を用いた,文字毎の特性について実験を行いましたので,紹介したいと思います.
Word2Vec とは
Word2Vec は単語をベクトル表現に変換する方法です.
これまでは自然言語処理の分野では単語を扱う場合, one-hot の形式で文章内の単語を表現することが多かったです.
しかし,自然言語を機械学習で扱う場合や論文では,最近では必ずといっていいほど Embedding された状態,すなわち単語をベクトルに変換してから機械学習のアルゴリズムに与えています.
ではなぜ one-hot の形式ではなく, Embedding された状態に変換するのでしょうか?
それは one-hot の形式では,単語同士の関係性や意味が考慮されていないためです.
そこで単語同士の関係性や意味を学習するために Mikolov らにより, Word2Vec の手法が提案されました.
Word2Vec には大きく2つの手法があり, cbow と skipgram の2つが提案 1 されています.
この2つの手法での大きな違いは, cbow は着目している単語の周辺語を入力に与え, skipgram は着目している単語を入力に与えるといったものがあります.
これらの違いにより, cbow はたくさんの分布情報をなだらかにする効果があり,小さなデータセットでよく使われます.
一方, skipgram は着目する単語と文脈を新しい観点で扱うため,大きなデータセットに有効であると一般的に言われています.
また,Word2Vec 以降も GloVe 2 や FastText 3 というアルゴリズムが提案されています.
Char2Vecとは
Word2Vecを学習させる対象言語が英語の場合,各単語がスペースで区切られているため,スペースやピリオドなどで単語区切りのデータセットを作成します.
一方,日本語の場合は文章中に区切り文字がないため,一般的には分かち書きや形態素解析を行い,必要な品詞だけを抽出して学習させます.
しかし,Word2Vec にはアルゴリズムの違いだけでなく,言語モデルに与えるデータセットの種類を変えた Doc2Vec や Paragraph2Vec, Char2Vec があります.
今回,私達は対話文を文字単位に分割し,文字のベクトル表現を学習させる Char2Vec に取り組みました.また,学習は Gensim4 の Word2Vec ライブラリを利用し, cbow として学習させました.
学習結果
学習した Char2Vec の結果を文字分布図とアナロジータスクの2つで見てみたいと思います. 今回の実験では,全・半角や数字,アルファベット,平仮名,カタカナ,漢字など3,731種類の文字を対象としています.
文字分布図
文字分布図はある文字に近い文字を可視化する分布図です.
今回は,'1','a','あ','悲'の4文字についてそれぞれに近い上位50個の文字を表示しました.
すこしウォーリーを探せ感があるのですが,頑張って探してみてください.笑
まずは,数字をベクトル表現にした場合です.

数字が近くに集まっているのがわかるかと思います.図だとわかりにくいのですが,図の中に同じ数字が出てきています.その理由は全角と半角の違いによるものです. しかし,全角は全角同士,半角は半角同士で集まっているので,区別して学習していることが分かります.
次に,アルファベットをベクトル表現にした場合です.

アルファベットは単体で使われることもありますが,文章においてはアルファベット同士が組み合わさって意味が表現されます.したがって,アルファベットはアルファベットとして集まって表現されているのだと分かります.
そして,平仮名をベクトル表現にした場合です.

'あ' の近くには平仮名は集まっていないことがわかります.平仮名は単体では意味を表さず,文章中においては漢字と組み合わせて意味を表すので,分布図として漢字の中に紛れているのだと思われます.
最後に,漢字をベクトル表現にした場合です.

今回は'悲'という漢字を選択しました.目的として,感情や形容する言葉に使われる漢字なので,その近くには同様の漢字がある場合,漢字の意味をベクトルとして表現できているのではないかと考えられます.実際に図を見ると,'悲'という漢字の近くには,'楽'や'優','寂'など似た使われ方をする漢字が近くに集まることが分かりました.
アナロジータスク
アナロジータスクとは,単語の性質を演算として計算できるタスクのことです.
Word2Vec の魅力はたくさんありますが,単語をベクトル表現にできたことで演算が可能になったことは,その一つだと思います.
このアナロジータスクの例としてよくあげられるのが, king - man + woman = queen というものです.
今回の Char2Vec でも同様のものができるか確認してみます.
Gensim でアナロジータスクを解く場合, most_similar メソッドを利用します. most_similar メソッドの引数に positive として与えているものは加算, negative として与えているものは減算するものです.
それでは,実験結果を見てみましょう.
まずは,数字でのアナロジータスクを見てみましょう.
今回の例として, 5 + 1 -2 を計算してみました.
model.most_similar(positive=["5", "1"],["2"])
[('4', 0.9669662117958069),
('3', 0.9577144980430603),
('6', 0.9576835036277771),
('7', 0.952031672000885),
('8', 0.9488403797149658),
('0', 0.9165981411933899),
('9', 0.8589234352111816),
('5', 0.8185327053070068),
('7', 0.7915964722633362),
('8', 0.7892774939537048)]
驚くことに,正しく計算されています.
数字の組み合わせということもあり,以下の条件でありうる440件分のデータセットを作成し,正答率がどの程度か計算しました.
- "positive" と "negative" の中の数字は一致しない
- Char2Vec のため "positive" と "negative" の計算結果は 0~9 までの値域とする
def create_analogy_sets():
analogy_sets = []
answer_sets = []
for p1 in range(0, 10):
for p2 in range(0, 10):
for n1 in range(0, 10):
# p1, p2, n1 が同じ数字になる場合 skip する
if p1 == p2 or p1 == n1 or n1 == p2:
continue
# p1+p2-n1 が負の整数の場合 skip する
answer = p1+p2-n1
if answer < 0:
continue
# p1+p2-n1 が10より大きい正の整数の場合 skip する
if answer > 9:
continue
answer_sets.append(answer)
analogy_sets.append([p1,p2,n1])
return analogy_sets, answer_sets
def precision(analogy_sets, answer_sets, topn=1):
correct = 0
not_num = 0
for i in range(len(analogy_sets)):
p1, p2, n1 = analogy_sets[i]
for predict in model.most_similar([str(p1), str(p2)], [str(n1)], topn=topn):
try:
if int(predict[0]) == answer_sets[i]:
correct += 1
except:
print(predict)
not_num += 1
continue
return correct, not_num
モデルの戻り値を top1 と top3 の2パターンで評価しました.
まず,戻り値の種類についてですが, top1 と top3 の両方において,半角数字が返された率はでした.
次に,計算結果についてですが, top1 での計算結果では,の正答率となり, top3 での計算結果では,
の正答率となりました.
ちなみにですが,数字に限定した上でランダムに回答した場合, top1 では, top3 では
,すなわち
となるはずなので,ランダムで回答するよりも良い結果になっていることが分かります.
学習データが対話データなのでほとんど数字の関係性を教えられておらず,
また,文字として数を与え,候補として3,000文字以上ある中から正解できていることに驚きを感じます.
ちなみに,漢数字の場合は,
model.most_similar_cosmul(["五", "一"],["二"])
[('四', 0.7392055988311768),
('染', 0.7125757932662964),
('1', 0.7093852758407593),
('先', 0.709115743637085),
('三', 0.7078965306282043),
('4', 0.706843912601471),
('3', 0.7037045955657959),
('6', 0.7036187052726746),
('九', 0.7021587491035461),
('敏', 0.6988415718078613)]
これも回答できています.近しいアナロジーとして漢数字や全角の数字が挙がっていることは驚くべき結果です.ちなみに先程の計算用のデータセットの場合,漢数字が返答されている確率は,計算結果の正答率は
でした.
最後に,漢字同士によるアナロジータスクです.
漢字は偏や旁などの部首とそれ以外の部分から構成されます.
今回は,その知識を活かしてアナロジータスクをしてみたいと思います.
model.most_similar(["木", "林"])
[('森', 0.6414894461631775),
('谷', 0.6174930334091187),
('雲', 0.6121721267700195),
('川', 0.6072961688041687),
('松', 0.6014201045036316),
('崎', 0.5943500995635986),
('熊', 0.5926244258880615),
('村', 0.5882901549339294),
('峰', 0.5817473530769348),
('冠', 0.5709230303764343)]
model.most_similar(["山", "石"])
[('岩', 0.6268459558486938),
('熊', 0.6220624446868896),
('松', 0.6124925017356873),
('芹', 0.610385000705719),
('藍', 0.5979625582695007),
('木', 0.5863777995109558),
('滝', 0.5861614346504211),
('韮', 0.5789919495582581),
('井', 0.5788655281066895),
('森', 0.5647031664848328)]
驚くことに漢字の構成を組み合わせると意図する漢字が返されました. しかし,必ずしもそうなるわけではありません.
model.most_similar(positive=["草", "楽"])
[('悲', 0.5380357503890991),
('憎', 0.47937360405921936),
('惜', 0.4682950973510742),
('苦', 0.4587554335594177),
('休', 0.44919806718826294),
('寂', 0.44706428050994873),
('忙', 0.4312727451324463),
('欲', 0.4239286184310913),
('鼻', 0.42341917753219604),
('嬉', 0.4128988981246948)]
残念なことに,'草'+'楽'='薬'を期待したのですが, '悲','憎','苦'などの漢字が抽出されました. (薬で辛い経験をしたニューラルネットワークなのでしょうか...)
まとめ
今回は, Char2Vec についてと学習させて得られた興味深い知見を紹介させていただきました.
全体として,概ね数字やアルファベットなどの種類や漢字が持つ意味はある程度近い距離にまとまっており,うまく Enbedding されているようでした.
今回のデータセットは,対話データをベースとしていましたが,データセットを変えることでまた異なる知見が得られるかもしれません.
最後に,弊社では一緒に人の感情に寄り添った会話ができる AI を創出したい自然言語処理 エンジニアを募集しています.ご応募お待ちしております.
-
T. Mikolov, Efficient Estimation of Word Representations in Vector Space↩
-
J. Pennington, GloVe: Global Vectors for Word Representation↩
新卒研修の受講レポート~git編~
はじめに
はじめまして、2017年新卒エンジニアの親川と玄馬です。 本記事では、git研修でおこなった内容や得た学びについて紹介したいと思います。
そもそもgitとは何なのか、という方は以下のサイトを参考にしてください。
Gitを使ったバージョン管理【Gitの基本】 | サルでもわかるGit入門 〜バージョン管理を使いこなそう〜 | どこでもプロジェクト管理バックログ
研修の様子
前半は、先輩社員による座学形式の研修でした。gitを楽しく学ぼう、ということで内容は
gitの使い方
commitとbranchについての解説
歴史の取り込み方(merge, rebase)
となっていました。 研修で使用した資料は以下のページで見ることができます。
すごいGit楽しく学ぼう // Speaker Deck
gitの使い方ではリポジトリの作り方から、変更のステージング方法、commit・pushの操作、branchの操作を学びました。
操作だけでなく、commitやbranchはどういったデータ構造で表現されているかを知ることができ、この後に学ぶmerge操作の理解における大きな助けとなりました。
歴史の取り込み方の学習として、merge操作でのオプションによる動作の違いを学びました。
後半は演習として、gitを使う上で起こるトラブルを解決する「git challenge」の過去問に挑戦しました。問題は難易度別に分けて出題されるので、自分のレベルにあったものから解答することができました。
前半で学んだ操作を使いつつ、理解不足な情報は調べたり先輩社員や同期に質問して各自のペースで進めていきました。

ちなみに実際のgit challengeは、gitに関する問題にチームで挑戦し、時間内にいくつ解けるか!…という弊社主催の学生向けの技術イベントです。(第5回大会では4時間で18問に挑戦したそうです。)
問題の解き進め方
git challengeは、1問ごとに、以下のような流れで進めていきます。
問題のリポジトリをclone
問題の指示通りの状態になるようにリポジトリを修正
push
すると、採点サーバで自動的に問題の正誤が判定され、全体のランキングページで結果を閲覧できるようになります。
「pushが出来ない」という同僚を助けるようなシチュエーションや、そもそもcloneすらできないリポジトリもあり、様々な問題に対して解決案を模索していきます。
最後まで解けないような難しい問題もありましたが、終了後に解説をしてもらえたので非常に勉強になりました。
ちなみに、git challengeの問題の解き方だけでなく、自動採点などのインフラの話が気になる方は、以下のブログを是非読んでみてください。
git challengeの自動採点高速化に向けたインフラのハナシ - mixi engineer blog
得た学び
今回の研修でcommitについての理解を深めることができました。ここでは、commitについて学んだことを紹介したいと思います。
皆さんはgitの仕組みについて、どのように理解しているでしょうか?
私は、「変更があった差分情報を時系列に保存し、いつでも過去の状況に戻れる」といった大まかな理解しかしていませんでした。
git研修が始まり、commitが持つ「Revision」という値が、gitの仕組みを理解する上で重要だということに気づきました。
commitの大まかなデータ構造は、以下の通りです。
commitのデータ構造
| Revision | commitのSHA-1ハッシュ |
| Tree | ファイルのスナップショット |
| Parent | ひとつ前のcommitのRevision |
| Author | commitを作成した人 |
| Committer | commitを適用した人 |
Revisionとは、commitに対応する以下のようなハッシュ値です。
6fe9db43763ded8bbfd0b428894baa9bfc0b7d42
gitの操作をする上で、このRevisionは多くの場所で登場します。
commitのデータ構造の中にも、Parentという値にひとつ前のcommitのRevisionが入っています。
ひとつ前のcommit、そのひとつ前のcommit・・・と辿って行くことで、一番最初のcommitまで見ることができます。
branchのデータ構造にもRevisionが登場します。
私はbranchについて、枝を伸ばす・枝を分けるといったイメージを持っていました。しかしbranchの正体は、あるcommitのRevisionを指すポインタのようなものでした。
branchが指しているRevisionを新しいcommitのRevisionに変更することで、枝が伸びる・枝が分かれるような処理を実現しています。
意外と単純な仕組みだと思いませんか?これを知って、私はgitの仕組みの理解がしやすくなりました。
普段gitを使う際に、私はこれらのことをそれほど意識せずに使っていました。
しかし、データ構造や実際に行なわれる処理といった仕様を知ることで、branchやmergeについて曖昧だった部分も理解しやすくなります。
そういった理解ができていることで、gitで困った時の対応力が大きく改善されると実感しました。
おわりに
今まではgitのコマンドの機能や実行結果を把握している程度でしたが、改めて詳細な仕様を知り、実際に行われている処理を考えながらgitを使えるようになりました。
この記事を見て、gitに興味を持った方は、ぜひgit challengeにご参加下さい!
また、git challengeの概要や今までの様子などがまとまっている以下のページもぜひご覧ください。
mixi GROUP presents「git challenge」
問題の一部は以下に公開されていますので、興味がある学生の方は挑戦してみてはいかがでしょうか?
第1回git challengeの出題内容を一部公開します - mixi engineer blog
AWSのアップデートによるダイレクトコネクトへの余波
※こちらの記事は過去のブログから転載したものです。
XFLAG スタジオの上竹です。
普段は、ネットワークの設計・調達・構築・運用をしています。
今回、AWS のとあるアップデートに着目して書きたいと思います。
2017年8月29日より、VPC(Virtual Private Cloud) にCIDR を追加しVPC を拡張することができるようになりました。
VPC 作成時に指定するプライマリCIDR に加えて、任意のCIDR を追加することができます。
VPC の全てのCIDR ブロックで、ELB やNAT Gateway を含むすべてのAWS サービスを使用できます。
なお、現時点(2017/8/30)では、GovCloud とChina リージョンでは、本アップデートは利用できないようです。
このアップデートが、DX(Direct Connect) 運用ポリシーの変更に繋がった話をします。
これまでの制約
これまでVPC は、作成時に指定されたプライマリCIDR のみを持ちました。
また、そのプライマリCIDR を変更することはできません。異なるCIDR をもつVPC を作りたい場合、新たにVPC を作る必要があります。
このとき、VPC とそれに所属するプレフィックスは1対1の関係であり、VGW(Virtual Private Gateway) にアタッチできるVPC も1対1の関係です。
またDX のVirtual Interface とVGW の関係も一度対応づけたら、変更不可です。他のVGW をVirtual Interface に対応付けたい場合、Virtual Interface を削除し新たに作成するほかありません。
従って、DX 経由でBGP セッションを張っているオンプレミス側のルーターは、AWS から常に1つのプレフィックスのみを受信する状態になっておりました。
これまでの運用ポリシー
上記の制約を考えて、XFLAG スタジオでは以下のように運用ポリシーを設計しておりました。
DX 収容ルーターで、特に受信経路フィルターは設定せず、maximum-prefix 1 を設定します。
ピアアップ時、受信経路を全て拒否するフィルターを設定しておき、受信した1プレフィックスが意図したプレフィックスか確認してから経路許可します。
こちらの運用ポリシーで、VPC 利用者のオペレーションによる事故を防ぐことができました。
これは、以下の理由からです。
この運用ポリシーの最大のメリットは、経路フィルターを管理、メンテナンスするコストから解放されることです。
今回のアップデートにより課題となること
前述したVPC に任意のCIDR 追加可能となるアップデートにより、これまでの制約は変更され、運用ポリシーは破綻します。
まず、複数プレフィックスを受信する可能性があり、maximum-prefix 1 ポリシーが破綻します。
VPC 利用者がCIDR 追加することにより、DX 経由のピアを落とすことができる状態です。
次に、任意の(時に悪意のある)プレフィックスを受信する可能性があり、受信経路フィルターなしというポリシーが破綻します。
VPC 利用者が任意のVPC を追加することができ、吸い込みや経路のハイジャックが可能な状態です。
対策を立てるため、まずはすぐに検証を実施しました。
検証
検証項目
- VPC にCIDR が追加された時点で、広報経路に追加されるのか
- CIDR 追加から広報までの時間差は? CIDR 削除から広報停止までの時間差は?
- 完全に任意のCIDR を追加することができるか、またそれが広報されるか
検証環境
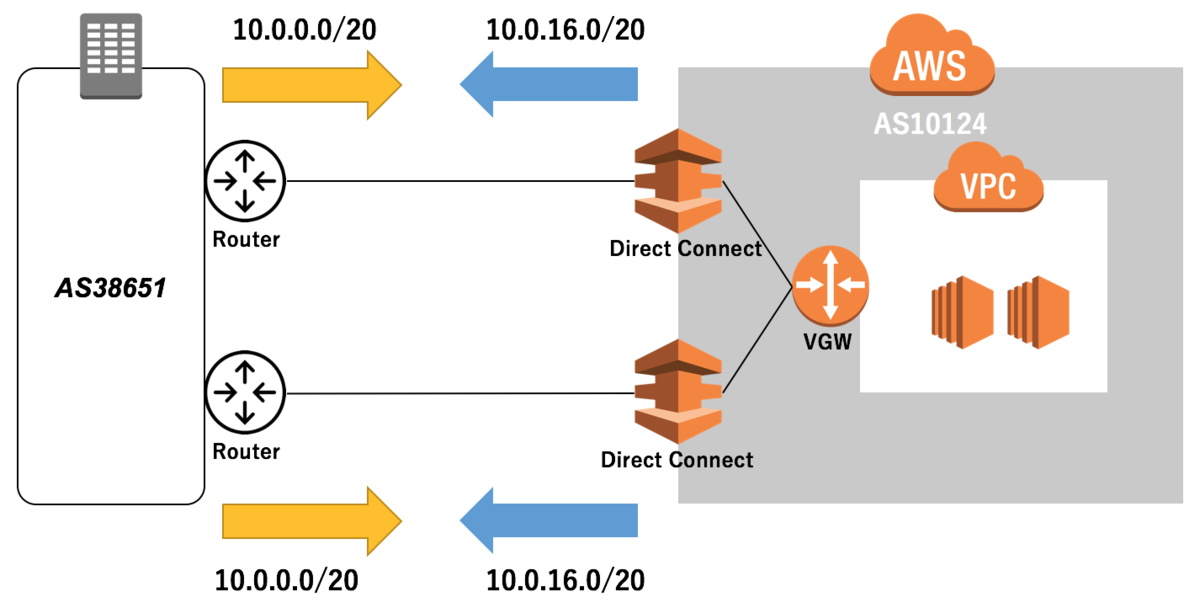
XFLAG スタジオでは、ルーティングテーブルが分離されているテナント環境が用意されており、各テナントが各クラウドと接続しています。
AWS との接続は、テナントごとにVLAN を使用してDX を共有しています。
検証用テナントが用意されており、このような時にも容易に商用テナントと同環境で試験することができます。
検証用テナントと接続されているVPC はプライマリCIDR 10.0.16.0/20 を持っています。
当然このプレフィックスをDX 経由で広報しています。
オンプレミス側からは、10.0.0.0/20 を広報しています。
検証結果
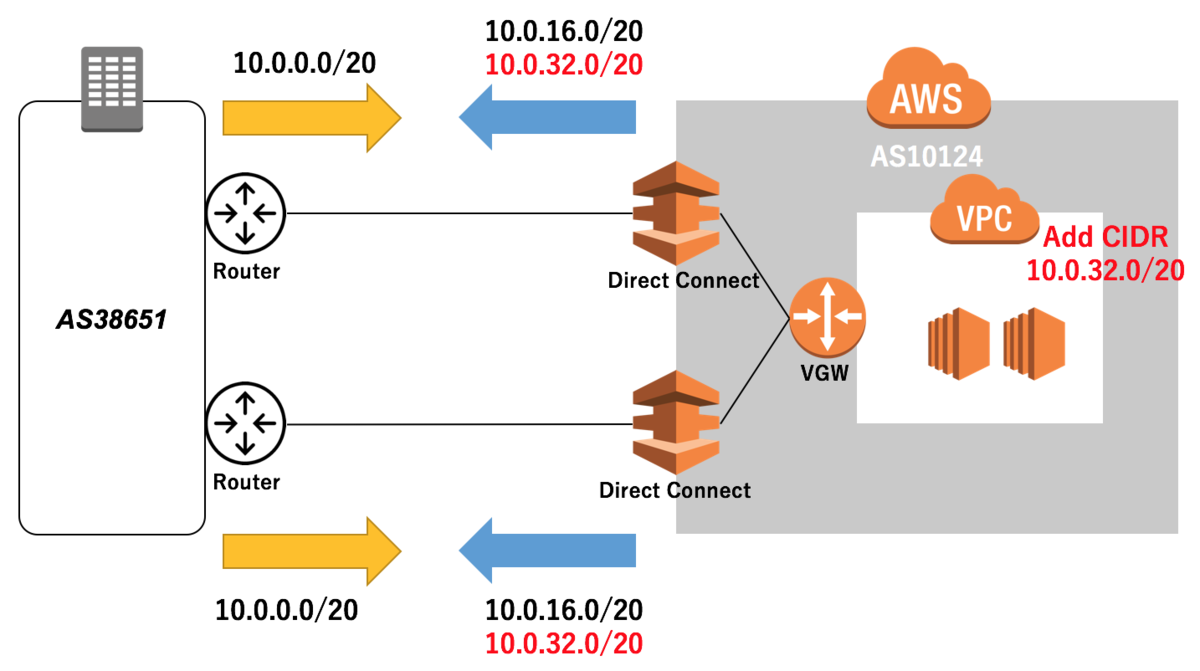
まず、VPC に10.0.32.0/20 のCIDR を追加しました。
CIDR を追加すると、そのプレフィックスが広報経路に追加されました。
VPC へCIDR を追加するオペレーションのみで、広報経路に追加されることがわかりました。
また、広報経路に追加されるまでの時間差ですが、我々の環境では2分ほどでした。
次に、追加したCIDR を削除してみました。
削除すると、10分ほど時間が経過してから、広報経路から削除されました。
この結果から、CIDR 追加のオペレーションミスをした場合、すぐに切り戻しても(逆の操作をしても)すぐには元の状態に戻らないことがわかります。
※ 時間差については、環境や今後のインプリによって変わる可能性があるかと思います。
本検証時のCloudTrail とルーターのログを以下に示します。
14:19:32 JST にCIDR 追加をして、14:21:47 JST にBGP アップデートがきていることがわかります。アップデート受信と同時に、maximum-prefix 1 設定により、ピアがダウンしています。
CloudTrail
{
※中略※
"eventTime": "2017-08-30T05:19:32Z",
"eventSource": "ec2.amazonaws.com",
"eventName": "AssociateVpcCidrBlock",
"awsRegion": "ap-northeast-1",
"sourceIPAddress": "xx.xx.xx.xx",
"userAgent": "signin.amazonaws.com",
"requestParameters": {
"AssociateVpcCidrBlockRequest": {
"VpcId": "vpc-xxxxxxx",
"CidrBlock": "10.0.32.0/20"
}
},
"responseElements": {
"AssociateVpcCidrBlockResponse": {
"xmlns": "http://ec2.amazonaws.com/doc/2016-11-15/",
"cidrBlockAssociation": {
"cidrBlock": "10.0.32.0/20",
"cidrBlockState": {
"state": "associating"
},
"associationId": "vpc-cidr-assoc-xxxxxxx"
},
"requestId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"vpcId": "vpc-xxxxxxx"
}
},
※中略※
}
ルーターログ
Aug 30 14:21:47mixi-router1-RE0 rpd[6618]: BGP_CEASE_PREFIX_LIMIT_EXCEEDED: xx.xx.xx.xx (External AS 10124): Shutting down peer due to exceeding configured maximum prefix-limit(1) for inet-unicast nlri: 2 (instance test-tenant)
Aug 30 14:21:47mixi-router1-RE0 rpd[6618]: bgp_rt_maxprefixes_check_common:9448: NOTIFICATION sent to xx.xx.xx.xx (External AS 10124): code 6 (Cease) subcode 1 (Maximum Number of Prefixes Reached) AFI: 1 SAFI: 1 prefix limit 1
Aug 30 14:21:47mixi-router1-RE0 rpd[6618]: Received malformed update from xx.xx.xx.xx (External AS 10124)
Aug 30 14:21:47mixi-router1-RE0 rpd[6618]: Family inet-unicast, prefix 10.0.32.0/20
Aug 30 14:21:47mixi-router1-RE0 rpd[6618]: RPD_BGP_NEIGHBOR_STATE_CHANGED: BGP peer xx.xx.xx.xx (External AS 10124) changed state from Established to Idle (event RecvUpdate) (instance test-tenant)
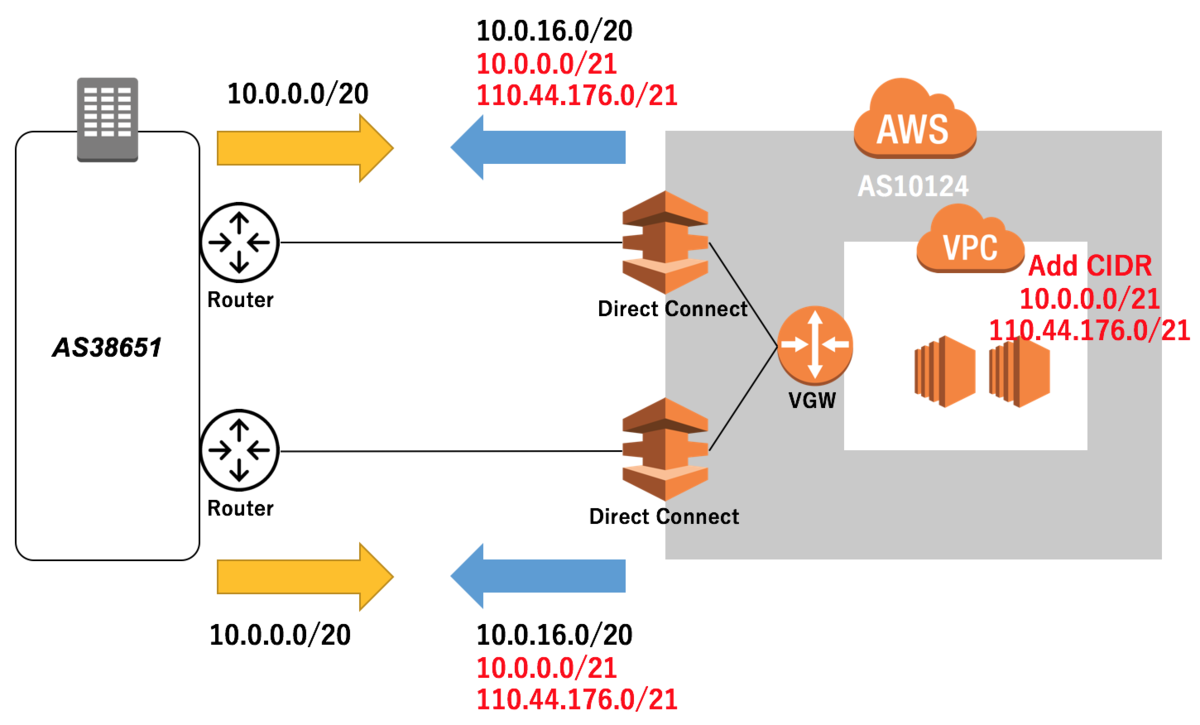
最後に、任意のCIDR を追加した場合どうなるか、検証しました。
まず、オンプレミス側から広報されている10.0.0.0/20 のmore specific な10.0.0.0/21 を追加してみました。
これも、広報経路にプレフィックスが追加されました。
これにより、ロンゲストマッチによって特定の経路の吸い込みができることがわかりました。
次に、グローバルアドレスを追加した場合どうなるか、検証しました。
XFLAG スタジオで持っている110.44.176.0/21 をCIDR 追加してみました。
こちらは追加操作時に弾かれるかと思いましたが、エラーなく入力でき追加されました。また、他のプレフィックスと同様に広報経路にも追加されました。
以上の結果から、任意のCIDR を追加可能で、それは全てDX 経由のピアへ広報される、ということがわかりました。
対応策
まずは、VPC 利用者に、CIDR 追加は利用しないように、追加したい場合は相談してもらえるように、周知/共有を実施しました。
ただし、これだけではリスクは潜在したままです。ポリシーを見直すことで対応します。
まず、maximum-prefix 1 を見直し、CIDR 追加操作によるピアダウンを避けます。
ただし、ある程度のプレフィックス数でmaximum-prefix N を設定します。自動化されたシステムとの接続には、防御手段を残しておきたいところです。
次に受信経路フィルターを適切に設定します。VPC 利用者と連携し、どのアドレスブロックを使用するか明確に相互に理解するようにします。
任意のプレフィックスが広報される可能性がある以上、今回のアップデートにより経路フィルターは必須となりました。
また、IAM にてVPC にCIDR 追加するイベントをdeny することを検討したいと思います。
まとめ
今回、ある機能アップデートが運用設計の見直しに繋がる一例の話をさせていただきました。
ポリシーの前提条件を理解することが大切で、前提条件が変わった場合はポリシーを見直す必要があるかもしれないと改めて気付かされました。
また、今回のように前提条件の変更は外的要因の場合もあります。常に、広い視野を持ってネットワークを運用していきたいです。
-
DX のピアに、maximum-prefix を設定している方は、見直しましょう
-
DX のピアに、受信経路フィルターを設定していない方は、設定しましょう
XFLAG スタジオでは、様々なポジションで積極採用中です。
ネットワークエンジニアも採用中です。
━・ネットワーク・サーバエンジニア採用中!・━
https://career.xflag.com/career/engineer/813/
https://career.xflag.com/career/engineer/872/
━━━━━━━━━━━━━━━━━━━━━━━