Tokyo TyrantによるHAハッシュDBサーバの構築
来年のバレンタインデーに、正確には「2009-02-14T08:31:30+09:00」に、UNIX時間が「1234567890」を迎えることを発見してちょっと嬉しいmikioです。さて、今回は高効率ハッシュデータベースサーバTokyo Tyrantを用いてHAハッシュデータベースを構築する手法についてご紹介します。ちょっと難しいし非常に長い内容なのですが、最後までお付き合いくださいませ。

可用性と保全性
HA(High Availability:高可用性)とは、可用性(Availability)が高いことです。それでは説明になっていないので詳しく言い替えますと、システムに障害が起きにくくすることと、たとえ障害が起きたとしてもできるだけ迅速に復旧できるようにすることです。データベース系のシステムはユーザのデータを管理するという中核的役割を担うため、可用性を高めることは最も重要な課題となります。可用性を測る指標として稼働率があります。これは単位時間内でシステムが正常稼働している時間の割合のことです。すなわち、障害発生間の平均間隔(MTBF: Mean Time Between Failure)と障害発生から復旧までの平均間隔(MTTR: Mean Time To Repair)の関数で、MTBF / ( MTBF + MTTR ) として定義されます。例えば1年のうちで364日間正常稼働してから壊れて復旧に1日かかるとすれば、稼働率は 364 / (364 + 1) = 99.726% となります。MTBFは信頼性(Reliability)の指標でもあります。
可用性の前提として保全性(Integrity)についても考える必要があります。保全性の指標としては、保全度があります。すなわち、障害前にデータベースに格納してあったデータを復旧後にきちんと回復できる割合です。例えば、100万件のレコードが障害復旧後に平均99万件を取り戻せたならば保全度は 99 / 100 = 99% ということになります。
...とかいうJIS規格の受け売りの話はそこそこにしておきますが、要は以下の3点をしっかりやって可用性と保全性を高めましょうということです。Tokyo Tyrantにはこれらを円滑に行うための仕組みがありますので、それについて詳しくご紹介します。- バックアップとリカバリ
- レプリケーション
- フェイルオーバー
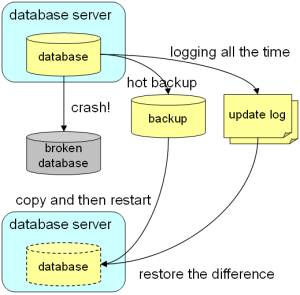
バックアップとリカバリ
考えたくないことですが、それなりの規模のソフトウェアには必ずバグがありますし、機械は必ず故障しますし、管理者は必ずミスをするものです。それによってサーバが落ちたり、さらにはデータベースが壊れることもそれなりの頻度で発生することは覚悟しておかなければなりません。データベースが壊れてユーザのデータが失われることはデータベースシステムにおいて最悪の事態なので、それを回避するために定期的にバックアップをとることは非常に重要です。

- サーバを起動する:(端末Aで)ttserver /tmp/casket.tch
- テストデータを入れる:(端末Bで)tcrmgr put localhost tako ika
- テストデータを検索する:(端末Bで)tcrmgr get localhost tako
- バックアップファイルを作る:(端末Bで)tcrmgr copy localhost /tmp/backup.tch
- サーバを落とす:(端末Aで)Ctrl-C入力
- データベースが壊れたことにする:(端末Aで)rm /tmp/casket.tch
- バックアップファイルをリストアする:(端末Aで)cp /tmp/backup.tch /tmp/casket.tch
- サーバを起動する:(端末Aで)ttserver /tmp/casket.tch
- テストデータを検索する:(端末Bで)tcrmgr get localhost tako
- 更新ログの置き場を用意する:(端末Aで)mkdir /tmp/ulog
- サーバを起動する:(端末Aで)ttserver -ulog /tmp/ulog /tmp/casket.tch
- テストデータを入れる:(端末Bで)tcrmgr put localhost tako ika
- テストデータを検索する:(端末Bで)tcrmgr get localhost tako
- サーバを落とす:(端末Aで)Ctrl-C入力
- データベースが壊れたことにする:(端末Aで)rm /tmp/casket.tch
- 更新ログを退避する:(端末Aで)mv /tmp/ulog /tmp/ulog-back
- サーバを起動する:(端末Aで)ttserver /tmp/casket.tch
- 更新ログをリストアする:(端末Bで)tcrmgr restore localhost /tmp/ulog-back
- テストデータを検索する:(端末Bで)tcrmgr get localhost tako
レプリケーション
バックアップと更新ログを併用する手法にも弱点があります。バックアップファイルや更新ログファイルを置いたディスクごとお亡くなりになった場合には復旧ができないということです。そもそも同じマシンに置いておいたらバックアップとは言えないので、バックアップファイルは別のマシンやテープ等のメディアに退避するのが普通ですが、記録中の更新ログファイルは移動できないのが頭の痛いところです。上記の問題を解決するために、レプリケーションという手法があります。あるデータベースサーバの更新ログを別のデータベースサーバに逐次転送して即座に実行させることでデータベースを多重化する仕組みです。便宜上、更新ログの送信元のサーバを「マスタ」と呼び、送信先のサーバを「スレーブ」と呼びます。レプリケーションの良いところは、マスタのデータベースとスレーブのデータベースは自動的に同期がとられるために、管理者は特になにもしなくても新鮮かつ信頼できるバックアップが維持されるということです。マスタが死んだ場合はスレーブをマスタに昇格させてさらにスレーブを追加すれば復旧できるし、スレーブが死んだ場合は新しいスレーブを追加するだけで復旧できます。バックアップファイルと更新ログからのリストアに比べるとダウンタイムもかなり短くて済みます。

レプリケーションの嬉しい副作用として、更新系のクエリはマスタに、参照系のクエリはスレーブに投げることによって、負荷分散ができることが挙げられます。1つのマスタに対して2つ以上のスレーブを繋げられるので、mixiなどの参照系のクエリが更新系のクエリに比べて圧倒的に多いようなシステムでは参照系の負荷をスレーブ間で分散できることには絶大な効果があります。MySQL等のRDBMSではバックアップのためというより負荷分散のためにレプリケーションを行うことも一般的ですが、全く同じ理屈がハッシュDBにもあてはまります。

- マスタの更新ログの置き場を用意する:(端末Aで)mkdir /tmp/ulog-master
- マスタのサーバを起動する:(端末Aで)ttserver -port 1978 -ulog /tmp/ulog-master /tmp/casket-master.tch
- スレーブの更新ログの置き場を用意する:(端末Bで)mkdir /tmp/ulog-slave
- スレーブのサーバを起動する:(端末Bで)ttserver -port 1979 -ulog /tmp/ulog-slave -mhost localhost -mport 1978 -rts /tmp/slave.rts /tmp/casket-slave.tch
- マスタにテストデータを入れる:(端末Cで)tcrmgr put -port 1978 localhost tako ika
- マスタのテストデータを検索する:(端末Cで)tcrmgr get -port 1978 localhost tako
- スレーブのテストデータを検索する:(端末Cで)tcrmgr get -port 1979 localhost tako
- マジックナンバ:1バイト:0xC9固定
- 日付:8バイト:更新クエリを受け取った日時のマイクロ秒
- サーバID:4バイト:更新クエリを受け取ったサーバのID
- コマンドサイズ:4バイト:コマンドのデータのサイズ
- コマンド番号:1バイト:コマンドの種類を表す番号
- パラメータ:可変長:コマンドのキーや値を直列化したデータ
- 結果コード:1バイト:コマンドの実行結果が成功なら0、失敗なら1
フェイルオーバー
「マスタ/スレーブ」のレプリケーション構成で保全性はかなり高まるのですが、可用性の点ではイマイチです。なぜなら、マスタが死んでからスレーブをマスタに昇格させるまでの間は更新操作ができなくなってしまい、その間は更新系の機能のダウンタイムとなるからです。「スレーブの設定をマスタ用に変えて再起動して、アプリケーションが接続するDBサーバを変更する」という手順を管理者が手動でやらねばならないのがこの問題の原因です。フェイルオーバーとは、この操作を自動的かつ暗黙裏に行い、ユーザからはあたかもデータベースサーバが落ちていないように見せる手法です。それを実現するためには「デュアルマスタ」もしくは「マスタ/マスタ」と呼ばれるレプリケーション構成を採用することになります。これは、2つのデータベースサーバを用意して、どちらに対する更新のログも一方から他方に送信するということです。可用性の文脈では「ホットスタンバイ」と呼ばれることもあります。

基本的には更新クエリは常に決まった方のサーバ(アクティブマスタ)に対して投げるようにして、他方のサーバ(スタンバイマスタ)は放っておくかスレーブとしてのみ使います。ただし、アクティブマスタへの接続に失敗した場合にのみ、スタンバイマスタに接続するようにしておきます。そうすることで、アクティブマスタが死んでもダウンタイムが一切発生しないようになります。ここで注意が必要なのは、通常時にはスタンバイマスタに対しては決して更新クエリを投げてはいけないということです。アクティブマスタとスタンバイマスタを交互に更新するとマスタ間の更新遅延によってデータの整合性がとれなくなる可能性があるからです。
それでは、デュアルマスタのレプリケーションを実際にテストしてみましょう。ここでも1台のマシンでポートを分けてアクティブマスタとスタンバイマスタを動作させることにします。端末は3つ開いておいてください。- マスタAの更新ログの置き場を用意する:(端末Aで)mkdir /tmp/ulog-a
- マスタAのサーバを起動する:(端末Aで)ttserver -port 1978 -ulog /tmp/ulog-a -sid 1 -mhost localhost -mport 1979 -rts /tmp/a.rts /tmp/casket-a.tch
- マスタBの更新ログの置き場を用意する:(端末Bで)mkdir /tmp/ulog-b
- マスタBのサーバを起動する:(端末Bで)ttserver -port 1979 -ulog /tmp/ulog-b -sid 2 -mhost localhost -mport 1978 -rts /tmp/b.rts /tmp/casket-b.tch
- マスタAにテストデータを入れる:(端末Cで)tcrmgr put -port 1978 localhost tako ika
- マスタAのテストデータを検索する:(端末Cで)tcrmgr get -port 1978 localhost tako
- マスタBのテストデータを検索する:(端末Cで)tcrmgr get -port 1979 localhost tako
- マスタAを一旦落とす:(端末Aで)Ctrl-C入力
- マスタBにテストデータを入れる:(端末Cで)tcrmgr put -port 1979 localhost inu neko
- マスタBのテストデータを検索する:(端末Cで)tcrmgr get -port 1979 localhost inu
- マスタAを復活させる:(端末Aで)ttserver -port 1978 -ulog /tmp/ulog-a -sid 1 -mhost localhost -mport 1979 -rts /tmp/a.rts /tmp/casket-a.tch
- マスタAのテストデータを検索する:(端末Cで)tcrmgr get -port 1978 localhost inu
アクティブかスタンバイかで接続先を切り替える責任をアプリケーション(またはクライアントライブラリ)に持たせるのも現実的なソリューションではありますが、アクティブとスタンバイを仮想的な単一サーバとして見せるためのプロクシに接続するようにすると、システムの透過性を高めることができます。そのようなプロクシ(ロードバランサ)はソフトウェアやハードウェアとして既に存在していますので、それらを活用するのもよいでしょう。
デュアルマスタは可用性を高める一方で、負荷分散には一切なっていないことに注意してください。可用性を高めつつ負荷分散をするには、2つのマスタそれぞれにスレーブをつけることが考えられます。しかしそうすると単一のデータセットを扱うために4台以上のサーバを用いることになるのでコスト(=お金と手間)の観点からは割に合わないかもしれません。ユースケースによっては、データセットをハッシュ関数等で分割してデュアルマスタのペアを分散させた方が現実的な場合もあります。mixiの日記データなどはまさにこのアーキテクチャで負荷分散をしています(MySQLベースですが)。
まとめ
Tokyo Tyrantのレプリケーション機構を用いて可用性と保全性を高めたハッシュデータベースを実現する手法について説明しました。テスト手順などはまだマニュアルに書いていないしそもそもマニュアルが英語なので、この記事がご参考になれば幸いです。この記事を読んで、「MySQLとほとんどおんなじじゃん」と思われた方も多いかと思います。そうなんです。MySQLのレプリケーション機構をほとんどパクって設計しました。MySQLを使った場合のノウハウは弊社でも世の中でも多く蓄積されているので、それに乗っておくのは妥当な判断だと言えると思います。Tokyo Tyrantもどんどんテストと運用実績を積み重ねていき、より実用性を高めていく所存です(暇があれば)。