続・技術的負債の把握と改善を促すために
こんにちは, 先日Kansai.pmで発表させて頂いたgoccyこと五嶋@たんぽぽグループです.
今回は, 前回紹介した技術的負債の把握と改善を促すためにの続編として, 僕が作ったPerl5コードのコピペ検出器について紹介させて頂きます.
はじめに
今やPerl, Ruby等さまざまな言語で, 便利なライブラリ群やフレームワークを利用できる時代になりました. これらを使うことでソフトウェアの開発コストは格段に下がり, より素早く開発することができるようになっています.しかし, 当初予定されていた機能を実装して, 「よしできたから終わり!」というわけにもいきません. 何か物を生み出せば, 必ずそれを保守・運用するコストが発生します. 開発することが便利になった今, 開発物を保守・運用することを支援するツールも求められています. ですが, 保守や運用, とりわけ保守に関して支援するツールはそれほどなく, 個々人のスキルに依存してしまっているのが現状だと思います.
開発物を保守することを支援するツールとして代表的なものは, リファクタリング(支援)ツールでしょう. リファクタリングツールを使うことで保守性の悪いコードを洗い出し, 改善するきっかけを与えてくれます.
今回は, リファクタリングツールが提供する機能の中でも代表的な, 重複コード検出機能をPerl5コードに対して実装した話をしたいと思います.
なぜ今までPerlにコピペ検出器はなかったのか
コピペ検出器と聞いてまず思い浮かぶのは, 学生の書いたレポートのコピペを検出するツールではないでしょうか?(コピペルナー)
では, ソースコードに対してコピペを検出するツールはどのくらいあるのでしょう? ざっと確認してみたところ, Java,C/C++,PHPなどに対するコピペ検出器は存在しますが, Perlに対するコピペ検出器は存在しませんでした.
ではなぜないのか?その理由の一つとして, Perlの構文が(解析する側からすると)非常に難解であり, コピペ検出するために必要な構文解析をすることが難しいということが挙げられると思います. (Only perl can parse Perl)
「そもそもコピペ検出するのに構文解析までする必要はあるのか?」と疑問をもたれた方のために補足しておくと, ソースコードのコピペ検出は単純な文字列一致ではできません.
文字列一致で検出しようとすると, 空白・改行が一つ入っているだけで後は全て同じコードであっても, コピペとは判断できません. また, 一文字ずつずらしながら重複検出することは, Rabin Karpなどの重複検出に適したアルゴリズムを用いたとしても気の遠くなるような計算量です. 解析するコード量が多くなれば, とても現実的な時間内では終わらないでしょう. 他には, 「変数名だけ違うけれども同じ処理」なんていうのも当然検出できません.
そこで構文解析が必要になります.
構文解析をすると, 空白・改行・コメントなど本来のコードに関係ない部分は全て除くことができます.
また, コードをトークン(意味のある最小単位)に分解できているので, 一文字ずつ調べる必要もありません
(例えば, $self をわざわざ「$」と「s」とに分ける必要はありませんよね). 更にいえば, 「このトークンは変数名だ」という情報もとれるので, 変数名を揃えてから重複検出することもできます. つまり, 構文解析をしてからコピペ検出すると, 検出速度や精度が格段に良くなります.
まとめると, Perlの構文解析は非常に難解で, トークンに分解するのも一苦労です.
そのため, 構文解析を必要とするコピペ検出器が存在しなかったのだと考えられます.
ないのであれば, 作りましょう
Perlの構文解析が難しいことはわかります.
しかし, 僕には以前C++で作っていたPerlの構文解析器がありました(正確にはトークナイザ+αといったものですが).
これを利用すれば, 自作していた構文解析器の完成度も上がるし一石二鳥です.
ふとPerlの構文解析モジュールとして有名なPPIが頭をよぎりましたが, Pure Perlなこと(遅い)と,
今回構文解析器に対して要求することを満たしていない(次で詳しく説明します)ということで, 採用しませんでした.
次項からは, 作成したモジュールについて紹介します
Compiler::Tools::CopyPasteDetector
今回作成したモジュールは, Compiler::Tools::CopyPasteDetectorというモジュール名でgithubに公開しています.
CPANには, 細かいバグやTODOリストを消化した後に上げる予定です.
モジュール自体の詳細な説明に関しては, こちらにまとめたので, 興味のある方はぜひ一読ください.
ここでは, 本モジュールの特徴や, どうやって作ったのかという実装よりの話, mixiでの利用方法について簡単に紹介しようと思います.
特徴
1. 速い!
構文解析器は全てC++で実装してあり, 検出処理はXSとPOSIX Threadを使って実装してあるため, 並列検出も可能です. 比較対象がないのであまり大きなことは言えませんが, それなりに速いのではと思っています.2. 正確!
mixi内の全ソース(15万行程度)に対して実行しても, 構文解析器のエラーもなく, 高精度な検出ができています. 他にはCatalystやMojoliciousといった少し大きめのモジュールに対しても実行し, 動作検証しています.3. 多機能!
ビジュアライザや豊富なサンプルが含まれています
ビジュアライザでの表示例
(繰り返しになりますが, 詳細な説明は上記のドキュメントをご参照ください)
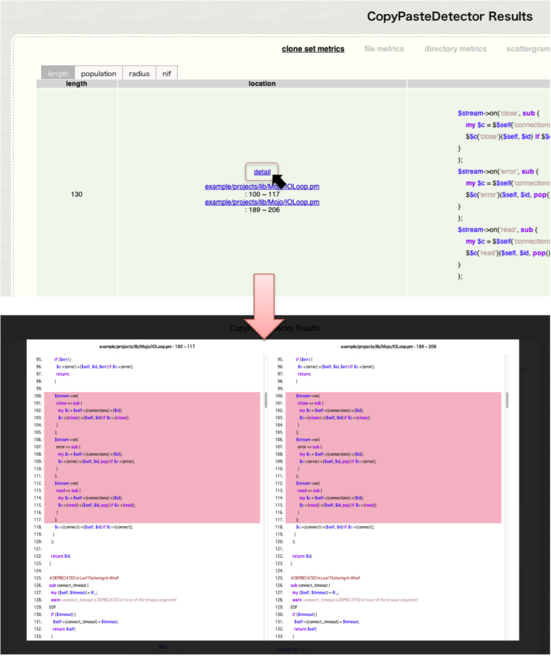
1. コピペされたコード片をスコアリングし, 順に表示

2. 元のソースで比較表示(コピペ部分は背景色を変更して表示)
3. 散布図の表示

まだまだ改善の余地はありますが, 上記で示したコンセプトを持ちつつ開発しています.
どうやって作ったか
大まかに処理を分けると, 次のようなステップで構成されます.- Perlで書かれたソースコードをトークン列に分解する
- 変数名のゆらぎをなくすオプションが有効の場合は, 得られたトークンの中から変数名のトークンを見つけ, 変数名を統一する
- トークン列を, コピペ検出をする上で意味のある単位にまとめ, 抽出する
- 得られたコード片をB::Deparseを使ってコンパイルする.
- コンパイル後のコード片をハッシュ化する
- コード片が隣接しているものの場合は, それらをまとめたものも作成しハッシュ化する
- ハッシュ値が同じものどうしをコピペコードとして抽出する. このとき, 対象コード片を含む, より大きなコード片がコピペ対象になる場合は, そちらをコピペコードとして採用する
※3.で書いた「意味のある単位」とはStatement(文)単位を表します.
Statement(文)とは, 処理が完結する最小単位とも言い換えることができ,
ソースコードの構造を大まかに次の4種類に分けたときの一番大きなまとまりです.
Statement(文) > Expression(式) > Term(項) > Value(値) (左にある物は右にあるものを含む)
例を挙げてみます. 「my $b = $a[0] + 1; 」という文があったときに,
「$a[0] + 1 」 (式)や「$a[0]」 (項)や「0」「1」 (値) ではそれ自体で処理が完結しませんが, 文全体で見れば完結しています(当たり前と言えば当たり前ですが...)
コピペコードは, あるまとまった完結する処理であることが多く,
それはつまり, 式や項だけではなく文単位でコピーすることが多いことを意味します.
そのため, Statement単位でコード片を取得します.
これによって, 式や項といったStatementよりも粒度の小さい単位を無視することができ,
計算量を大幅に減らすことができます.
ここで, 前項で触れたPPIを採用しなかった理由について説明すると,
PPIではStatement単位でコード片を取得し,
かつ元になったソースコードの行番号を取得するAPIがなかったため, 採用を見送りました.
(元の行番号は, 検出結果表示のときに必要になります)
※ 4. B::Deparseでコード片をコンパイルし, Perlが実行する直前の状態に表記を統一します. これによって, ある程度書き方のゆらぎを統一化することができます.
(しかし, B::Deparseが速度の面でボトルネックになってしまっているという問題もあります)
mixiでの使われ方
mixiでは, 本モジュールを技術的負債の把握と改善を促すためにと同じスキームで運用しています. つまり, リビジョン毎にサービス(Namespace)単位でコピペに関する様々なスコアを算出して比較し表示しています. これによって, 適切なリファクタリングタイミングを判断することができ, 効率的に負債返済に取り組むことができるようになります. 詳しくは, リンク先をご参照ください.参考までに, ビジュアライザでの表示例を載せます(値はダミーです)
1. 直近のNamespace間のスコア比較

2. Namespace毎のスコア表示

また, このmixiで行っている取り組みを他でも利用して頂きたいと思い,
運用に必要な実装を全てモジュール内のexample/extension以下にまとめました.
ドキュメントもこちらの応用例の項目で紹介していますので, ぜひ読んで使ってみて頂ければと思います.
まとめ
Perlコードのコピペ検出器, Compiler::Tools::CopyPasteDetectorについて紹介しました. (完全に個人で開発したもの, かつ大きめのモジュールなのでところどころバグっているかと思いますが, そのときはgithubのIssuesに報告して頂ければ幸いです. できる限りすぐ対応します)
小規模から大規模なコードまで, 様々なケースに利用できると思いますので,
ぜひ本モジュールを使ってコピペコードを撲滅して頂ければ幸いです.
-コピペを目で見つける時代は終わりました-
面倒なことは全てコンピュータに任せましょう