新RSS Crawlerの裏側
このブログでは初めましての長野雅広(kazeburo)です。mixi開発部・運用グループでアプリケーションの運用を担当しています。
12月12日よりmixiのRSSのCrawlerが改善され、外部ブログの反映が今までと比べ格段にはやくなっているのに気付かれた方も多いかと思います。この改善されたRSS Crawlerの裏側について書きたいと思います
以前のCrawlerについて
以前のCrawlerは{kind=link}

- cronからbrokerと呼ばれるプログラムを起動
- brokerはmember DBから全件、idをincrementしながら取得し、外部ブログが設定されていればcrawlerを起動(fork)
- crawlerはRSSを取得しDBに格納して終了
構築にあたり
新しいCrawlerを構築するにあたって、- 監視可能であること
- 管理・運用できること
- スケールすること
- 処理の分散を行う
- 処理途中でのスクリプトのデプロイを可能にする
- 長時間動作し続けるプログラムでDBへの接続はしない
- モダンなRSS解析エンジンを利用する
新システムの概要
そして12月12日に正式に稼働しはじめたCrawlerのシステムは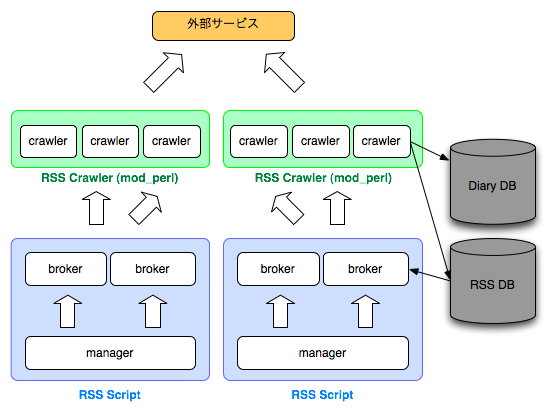{kind=link}

+---------------+---------------------+ | Field | Type | +---------------+---------------------+ | member_id | int(10) unsigned | | diary_url | varchar(255) | | rss_url | varchar(255) | | status | tinyint(3) unsigned | | last_modified | datetime | | last_crawl | datetime | | fetcher_seed | tinyint(3) unsigned | +---------------+---------------------+fetcher_seedは60までのランダムな数値が入っています。このランダムの数字はあとで使います。
サーバは2種類に分かれ、RSS ScriptとRSS Crawlerになりました。Scriptサーバにはmanagerとbrokerがあり、Crawlerサーバではcrawlerが動きます。
crawlerはmod_perlのHandlerとして動作させました。実装も一新し、Plaggerを参考に といったPerlモジュールを利用しています。crawlerはアクセスを受けるとparameterで渡されたurlからRSSを取得して日記のDBやRSS DBを更新します。crawlerはApacheのMaxRequestPerChildで指定されている数までは動き続けるので1件毎のforkがなくなりました。cronに代わり、crawlerシステムの司令塔としてPOEで作成したデーモン、managerを作成しました。managerは2秒毎にbrokerを監視し一定数のbrokerを起動します。確実にbrokerを動かすために長時間(20分)動いているbrokerを自動でkillします。また指定されたPortをListenし、telnetなどでbrokerの起動数を確認できます。これを用いてnagiosからcrawlerの監視を行っています。
brokerはmanagerから起動され、RSS DBから前回の巡回から2時間以上たっているurlとmember_idを取得します。取得時のSQLにはfetcher_seedを含めます。fetcher_seedはmemcachedのincr機能を利用して取得した数字を60で割った余りを使います。
my $incr = $cache->incr( $FETCHER_SEED_KEY );
my $sth = $dbh->prepare("SELECT * FROM rss WHERE last_crawl <= ? and fetcher_seed=?");
$sth->execute(
'2007-12-21 14:14:00',
$incr % 60
);
このようにすることで、複数のプロセスで巡回が行われていても同じ処理が走らないようにできます。
DBから取得したurlとmember_idをHTTP::Asyncという非同期にHTTPのRequestを行うモジュールを使ってcrawlerに渡します。最大1000件のリクエストを行った後brokerは正常終了します。
処理の流れをまとめると
- managerはdaemonとして起動
- managerがbrokerを起動
- brokerはRSS DBからurlを最大1000件取得しcrawlerに1件毎非同期にリクエスト
- crawlerは外部サービスからRSSを取得して日記DBに保存、RSS DBの最終巡回時間を更新