OpenStackとLXCを導入した話
こんにちは、運用部 アプリ運用グループの清水です。Golang鋭意勉強中です。
今回は、SNS「mixi」に限った話ではなく、ミクシィ社全体として利用している仮想環境について紹介したいと思います。パブリッククラウドも一部のサービスで利用していますが、今回は、自社で運用している仮想環境にフォーカスして書いてみようと思います。
今まで利用してきた仮想環境
今まで利用してきた仮想環境というと、手作業で構築したKVM(Kernel-based Virtual Machine)環境が中心でした。手作業といってもある程度手軽に構築できるように、シェルスクリプトとCobblerでVMを構築できるようになっています。構築の流れは以下のとおりです。
- CobblerにVMのIPやホスト名などをスクリプトで登録する。
- KVMのホスト上でスクリプトを実行(koanコマンドでCobblerと連携してVMをセットアップ)
VMの数が少ないうちは、この方法でも問題は大してありませんが、VMが増えてきたり用途が多様化してくると、VMの管理や物理障害時の対応が非常に面倒になるという課題を抱えてきました。
OpenStackの導入
2013年の春頃にOpenStack Grizzlyの検証を始め、同年の夏頃には、このOpenStack環境を本番環境としてサービスが動き始めました。社内ではこの環境を「Gizmo(ギズモ)」と呼んでいます。名前の由来はご想像にお任せします:-p
Gizmoを構築した背景としては、従来よりも低コストでスピーディーな開発・リリースを実現する環境が求められていたことにあります。なるべく運用者の手を介さずに、開発者主導でサービスの開発とリリースできるように、デプロイツールとセットで環境を提供して、PaaSとして使える環境を整備しました。OpenStackを導入したことで、従来のように手作業でKVMを構築する煩雑さから解放されました。
Gizmoでは、データベースとしてMySQL、KVSとしてRedis、CIとしてJenkins、ログや画像のストレージとしてRiak CSを使えるようにしています。デプロイしたインスタンスは、Zabbixによって自動的に監視・モニタリングされます。
Gizmoの利用者は以下の流れで使うことになります。
- チケットでGizmo利用の申請(運用者が利用者に各種認証情報とデプロイサーバを提供する)
- インスタンスを起動
- デプロイ用のサーバで専用のツールを使って、Gitレポジトリからコードを取得してデプロイの繰り返し
- リリース
基本的には利用者主導で開発・テスト・デプロイ・リリースのサイクルを素早く回していくことになります。運用者は、IRCの専用チャンネルでGizmoに関するサポートをおこない、あがってきたフィードバックをもとにGizmoを改善しています。
開発環境の改善
ミクシィでは従来より、開発者一人ひとりの手元のマシン(Windows、Macなど)と、リモートの開発環境(Linux)を提供しています。開発者は、手元のマシンでVagrantを使って開発することもできるようになっていますが、マシンのスペックによってはリソース不足になったり、使い方によっては常時安定して起動しているリモート環境のほうを好む場合もあります。
前述の通り、従来はKVMホストにVMを手作業で構築して提供してきましたが、Gizmoと同様に開発者主導で環境の構築ができるようにOpenStackを導入しました。開発環境の場合はPaaSではなくIaaSとして提供し、開発者はVM内をroot権限で自由に扱えるようにしています。
開発環境OpenStackの構成
OpenStackのバージョンはGrizzly 2013.1を使っています。検証当時から使っているバージョンなので、そのまま使い続けています。OpenStackの各コンポーネント毎の構成について、非常に簡単に書いてみます。
- 認証(Keystone)
- LDAPと連携。個人ごとにテナントを切ってクォータ設定。
- ネットワーク(Quantum)
- Linux BridgeでTagged VLAN構成。
- イメージ(Glance)
- VeeweeとChefで作成したイメージを登録。
- インスタンス(Nova)
- SSD上にイメージを展開して、いわゆるEphemeral Storageとしての性能を高めています。
- ストレージ(Cinder)
- 利用者が自由にアタッチ。CinderホストのディスクはRAID5構成。LVMのボリュームが切り出され、iSCSIで接続されます。
mixiの本番環境にLXCを導入
一部の本番環境と開発環境でOpenStackを使ってきましたが、2013年の10月頃から新たにLXC(Linux Containers)の検証を始めました。翌月にはmixi向けの本番環境でLXCの運用が始まり、現在ではアプリケーションサーバの大半と、 Reverse Proxyサーバの一部がLXCインスタンスとして動作しています。
LXCは、KVMのようにハードウェアなどのエミュレーションの上に仮想マシンを動作させるのではなく、プロセスやネットワーク、ユーザー空間などを分離して、仮想的な環境(以下、インスタンスと呼ぶことにします)を提供します。Kernelの機能を使って分離された環境なので、LXCインスタンスではKVMで起きていたようなCPUやディスクIOなどのパフォーマンス劣化が基本的に発生しません。この点がLXCを使う大きなメリットと言えます。他のメリットとしては、インスタンスの起動が速いことが挙げられます(init以降の起動だけなので当然といえば当然)。
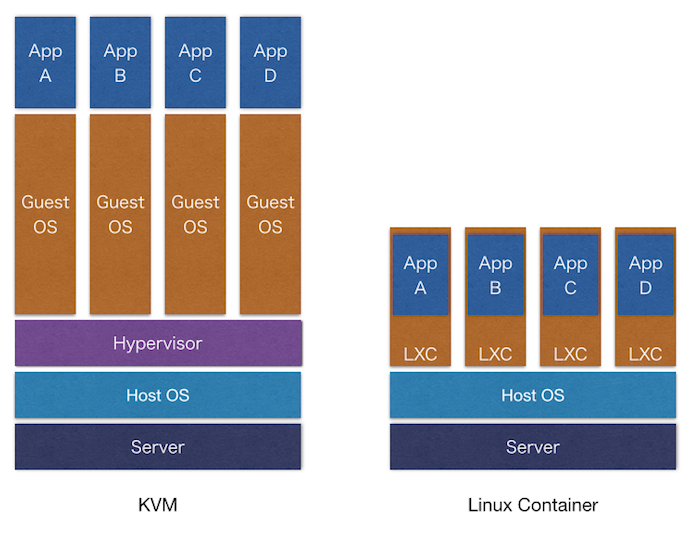
mixiでは様々な機能が存在し、アクセスの頻度も非常に高いため、より性能が求められます。KVM環境では性能が十分に出せず仮想化を積極的に進めることができませんでしたが、今回のLXCの導入により、高い性能を維持しながらマシンリソースを効率よく使った構成を作ることができるようになりました。
LXCは検証当時の最新版である0.9.0を使っています(最近1.0がリリースされたのでいずれ乗り換えられたらいいなと思っています)。Kernelは3.10。また、LXCといっても今流行りのDockerは使っていません。当時試したDockerのバージョンではNAT構成が前提となっていたため、弊社のネットワーク環境に適していませんでした。
そこで、より自社内のネットワーク構成にマッチしたLXC環境を効率良く作るために、Trailer(トレーラー)と呼ばれるツールを開発しました。開発した背景には、Dockerのような成長の激しい多機能なミドルウェアを単に使うのではなく、必要とした機能だけを実装したツールで運用してみたかったという思いがありました。
最近では、Dockerのネットワーク周りの実装が変わっているかもしれませんし(ちゃんと追えていません)、pipeworkを使って構成する手もありそうです。
Trailerとは
Trailerとは、Rubyで書かれた内製のコンテナ管理ツールです。コンテナを扱うツールということからトレーラー(コンテナを運ぶ牽引車)という名前が付けられました。Trailerは、レポジトリサーバに格納されているLXCインスタンスのイメージファイルを必要に応じてダウンロード、展開、起動するといった手順をコマンドで実現しています。具体的にどういったコマンドで行うのかについては次に説明します。
Trailerの動作フロー
Trailerの動作フローについて簡単に紹介します(今回詳細は割愛しますが、別の機会があれば書いてみたいと思います)。

インスタンスの起動フロー
- あらかじめ作られたイメージをレポジトリサーバからダウンロード(trailer pull)
- イメージを起動(trailer start)
- ローカルにダウンロードされたイメージをインスタンス用のディレクトリに展開
- ARMと呼ばれる内製のアドレス管理ツールに対してAPIアクセスし、IPアドレスとMACアドレスが払い出されます(ARMはAPIアクセス可能なDHCPサーバのようなもの)。
- 取得したIPアドレスとMACをインスタンスに設定(macvlan bridgeモード)して、init(systemd)を起動します。
- trailer start実行からsshで接続可能になるまでにかかる時間は10秒程度(イメージサイズによって多少の変動はあります)。
インスタンスの停止フロー
- 停止コマンドを実行(trailer stop)
- LXCのプロセスの停止、ディレクトリの削除
イメージの作成とレポジトリサーバへのアップロードのフロー
- ベースとなるイメージを起動(trailer start)
- インスタンスに対してChefでレシピを適用(knife-soloを利用)
- ルートファイルシステムをrootfs.gzとして圧縮する(trailer snapshot)
- イメージ情報が書かれたyamlファイルとrootfs.gzをtarballにする(trailer archive)
- レポジトリサーバへアップロード(trailer push)
Trailerが扱うイメージファイル
Trailerが扱うイメージファイルは、OSのルートファイルシステムをそのままtarballにしたものです。ただし、イメージを起動するためにはinitが動けばよいだけなので、イメージ内にGRUBやKernelは入っていません。また、Dockerが対応しているAUFSには現在対応していません。
LXCを使った事例
LXCを使った事例についていくつか紹介します。
アプリケーションサーバとmemcached
アプリケーションサーバは、メモリを使い切る前にCPUを使いきってしまうことが多いため、メモリが余ってしまうことがよくあります。そういった場合にメモリを有効活用するために、LXCインスタンスを立てて、余ったメモリをmemcachedプールの一部に使っています。しかしLXCにせずとも別プロセスでmemcachedを起動すればいいのではと思うかもしれません。LXCにする理由は以下のとおりです。
- インスタンスごとのリソース利用状況を把握しやすい。
- cgroupsによるリソース制限ができる(たとえば、片方のインスタンスのリソースが過剰に使われて、他方のインスタンスに影響を及ぼさないように設定することができる)。
- インスタンスごと捨てて、新しくインスタンスを立てて、別の用途に切り替えることが簡単にできる(いわゆるImmutable Infrastructureの考え方)。
Reverse Proxy
複数のReverse Proxyサーバ用のLXCインスタンスを1ホスト上に立ち上げ、それぞれにグローバルIPとプライベートIPを割り当てています。1物理ホスト1Webサーバだとリソースが効率よく使えない(メモリなどが余ってしまう)場合に適しています。
その他
他にも一部のジョブキューやKVS、配信サーバなどをLXCインスタンス化して、リソースの効率化と集約を図っています。
LXCを使う上で気をつけること
物理サーバやKVMを運用する時以上に気をつけなければいけない点について書いてみます。
スレッド数やPID数に注意
多数のインスタンスを起動して、多数のプロセスやスレッドが生成されると、ホスト側のスレッド上限値に達したり、PIDが不足しやすいので注意が必要です。たとえば、1台の物理サーバ上に、LXCのインスタンスを5個起動して、それぞれにインスタンスに10,000個のスレッドが生成される(合計50,000スレッド)、といったことも十分に考えられます。こういった場合には、
kernel.threads-max kernel.pid_max vm.max_map_count
あたりを増やしておくことと、
/etc/security/limits.d/90-nproc.conf
の制限値を unlimited にしておくと安心です。その他にも、用途に応じてFile Descriptor数や、TCP/IP周りのKernelパラメータの調整が必要になります。ただ、インスタンス側では設定できないKernelパラメータがあったりするので、sysctlやechoなどで設定する際に要注意です。
利用リソースの予測
当然のことですが、用途や起動予定のインスタンス数から全体のリソースの利用率をあらかじめ予測して設計しておかないと、ホスト全体としてのリソースが溢れてしまったり、OOM Killerが発生したりと大きな問題が発生してしまいます。cgroupsで制限することも有効かもしれませんが、上限値に達してしまうことはあまり良くないので、リソース利用量の正しい見積もりが必要です。
cgroupsではディスク容量の制限はできない
cgroupsではインスタンス単位のディスク利用量の制限ができません(ディスクIOの制限はできます)。もし、インスタンス単位でディスク容量の制限をしたい場合は、たとえばホスト側でLVMボリュームを制限したいサイズごと切って、そのボリューム上にLXCインスタンスのディレクトリツリーを置くようにすると擬似的な制限ができます。KVMではイメージのサイズで制限されますが、LXCでは制限できないので要注意です。そのため、ホスト側のディスク容量のモニタリング、監視は必須です。
インスタンス単位のCPU利用率やメモリ利用率を取得できるようにする
LXCインスタンスを運用していくには、各種統計値をモニタリングして、動作に異常がないかどうかを日頃から監視していく必要があります。しかし、LXCインスタンスのCPU利用率やメモリ利用率は、cgroupsの管理下となっているため、 /proc/meminfo や /proc/stat などを元にしているSNMPの値からだけでは実際の利用率が正しく取得できません。
cgroupにおけるメモリ上限は
/sys/fs/cgroup/memory/lxc/インスタンス名/hierarchical_memory_limit
の値、CPU利用率は
/sys/fs/cgroup/cpuacct/lxc/インスタンス名/cpuacct.stat
の値から統計値を取得することができます。ミクシィではそれらの値からグラフを生成してモニタリングをおこなっています。
まとめ
OpenStackは触り始めて約1年、LXCは約半年と、まだあまり時間が経っていませんが、どちらに関しても本番での運用ができてとてもよかったと思っています。マシンの利用効率も格段に良くなりました。
今後もOpenStackやLXCなどの新しい技術によって、ハードウェアリソースの効率化、作業・管理の効率化を実現し、高性能で運用しやすい環境作りを進めていきたいと思います。